Estimación de una muestra aleatoria
Para la estimación de una muestra de la cantidad de viviendas para el estudio se usa la siguiente fórmula estadística que se puede ver con detalle en CYMA (2012):
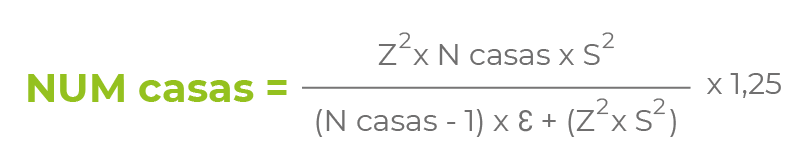
Donde:
NUMcasas = número de casas que incluirá la muestra
Ncasas = número de casas en el área de estudio
Z = coeficiente de confianza al 95% (1,96)
S2 = desviación estándar (kg/hab/día)
MARN (2018) recomienda el uso de 200gr/hab/día si no se tiene el parámetro de estudios previos.
ɛ = error de muestreo (entre 0,1 a 0,05 según el nivel de precisión buscado)
Es recomendable que se tome un porcentaje adicional de casas por muestrear, en caso de que en algunos casos algunas muestras se pierdan al momento de hacer el trabajo de campo.
Este porcentaje puede ser entre 10% y 25% de la muestra obtenida, según sean las dificultades previstas en el trabajo de campo.
La muestra puede estar compuesta por viviendas según estrato socio económico, por ejemplo en estrato bajo, estrato medio y estrato alto, o simplemente bajo y medio-alto, por ejemplo.
Los porcentajes de estos estratos deberían basarse en la composición de estos estratos recogidos en encuestas o censos, o se pueden usar parámetros nacionales, si ese fuera la única posibilidad.
Para conocer las zonas donde realizar el trabajo de campo, se puede hacer una demarcación y numeración de zonas del mapa del cantón las zonas por estudiar. Estas zonas deben clasificarse por estrato socio económico.
Una vez demarcadas, se elige aleatoriamente zonas de cada nivel socio económico y se divide el número de casas de la muestra en las zonas elegidas. Puede ser que una zona provea todas las casas que requiere el estrato, y se use una sola zona, pero si no se puede elegir una o dos adicionales para llenar el cupo.
Las casas se seleccionan por el método de muestreo simple aleatorio, que consiste en escoger de las zonas el total de viviendas, de tal modo que cada una tenga la misma posibilidad de ser escogida.
Cuando se seleccionan establecimientos comerciales y los industriales con residuos sólidos comunes, la muestra se expresa como:

Donde:
NUM est = número de casas que incluirá la muestra
N establecimientos = número de casas en el área de estudio
Z = coeficiente de confianza al 95% (1,96)
S2 = desviación estándar (0,3 kg/hab/día)
ɛ = error de muestreo (entre 0,1 a 0,05 según el nivel de precisión buscado)



